Disk Files Buffers
Architecture of a DBMS
SQL을 처리하기 위한 DBMS의 구조
= 계층화(Layer)를 통해 구현(유지보수 용이)
-> 데이터베이스 전문가들은 이러한 os, system을 이용하지 않고, 물리 장치의 구조를 파악한 뒤 직접 기록한다고 함(시스템을 이용하면 오버헤드가 발생하기 때문)

1. Query Parsing & Optimization
엄밀히 따지면 컴파일은 아니나, human friendly하게 쓰인 sql을 기계어로 번역하는 과정
parsing -> syntax check -> Relational Operator & Optimization(여러 query plan 중 가장 짧게 걸릴 것 같은 query plan을 추측하여 선택)

2. Relational Operators
Optimization 이전에 실행되는 단계로써, 파싱된 sql을 relational operators로 바꾸는 과정
여러 개의 relational operators(=query plan)가 나올 수 있고, 이 중에서 가장 최적이라고 생각되는 query plan을 채택하여 데이터를 읽어옴(=optimization)

3. Files and Index Management
필요한 데이터를 논리적인 형태로 접근할 수 있게 매핑을 시켜주는 단계
(논리적인 구조로 File -> Page -> Record의 형태를 가지고 있다.)
현재 계층에서 원하는 record를 찾을 수 있는데, 하위 layer에서 해당 record가 있는 page를 받아오고 offset을 통해 record를 얻을 수 있다.

4. Buffer Management
데이터 베이스가 저장되는 저장 장치는 속도가 매우 느리기 때문에, 이를 보완해주어야 함
(생략이 가능하지만 빠른 데이터베이스시스템을 위해선 꼭 필요한 단계)
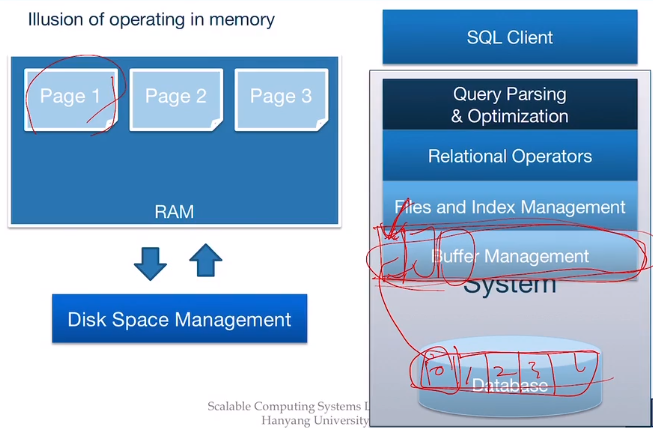
5. Disk Space Management
요구하는 페이지를 찾아서 반환하는 단계이며, 또는 빈 페이지를 할당해주거나 없애기도 한다.
몇 번째 페이지인지 요청하면 이를 실제 물리주소로 변환하여 돌려주며, read&write 시스템 콜을 이용하여 데이터를 저장한다.
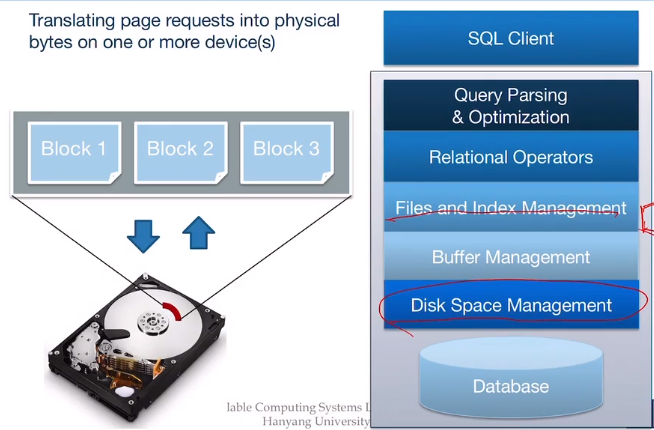
물리 장치들은 매우 느리기 때문에 Block Level 단위로 데이터를 내보내며, 보통 page의 단위보다 크게, 즉 한 블록 안에 하나 이상에 페이지가 들어갈 수 있도록 Block을 구성한다.(여기서는 page=block으로 단위를 구성)

+) 각 단계에서 반드시 병행 제어와 recovery를 고려해야한다.
필수적으로 file..., buffer..., disk... 이 3개의 단계에서는 병행 제어(locking)와 작업이 중간에 중단되었을 때 일관성을 유지할 수 있도록 recovery(logging)를 반드시 구현해주어야 한다.

File Representations - files(pages(records))
저장 장치에서 Page는 disk space manager가 관리하고, 메모리에서 Page는 buffer manager가 관리한다.
Disk Space Management에서 원하는 페이지를 얻기 위해, 알맞은 로컬 파일 시스템을 찾아서 block 단위로 데이터를 요청한다.


데이터베이스의 Files
DB File에서 원하는 record id를 얻기 위해서 page id와 offset을 알아야 한다.
또한, 이러한 record를 저장하고 꺼내는 데 다양한 기법이 사용될 수 있다.
크게 4가지 방법이 있고, 현대의 데이터베이스는 대부분 Index Files 기법을 사용한다.

1. Unordered Heap Files
순서없이 무작위로 heap(=흙더미, 일반적인 heap 구조의 의미와는 다름)의 형태로 record를 기록하는 형태

* 고려해야할 점
- 파일 안의 페이지들을 추적해야함
- 페이지 안의 여유 공간을 추적해야함
- 페이지 안의 record들을 추적해야함
방법 1) 파일을 페이지로 분할하고, 헤더 페이지를 통해 페이지 접근하는 방법

-> 알맞는 free space를 찾기 위해 탐색 시간이 소요
-> 원하는 record를 찾기 위해 모든 page 탐색해야함
방법 2) 헤더 페이지 안에 들어있는 meta 데이터를 보고 free space 정보를 찾음

* 나머지 방법들은 추후에 다룰 예정
Page의 레이아웃
- 레코드의 길이가 고정인지 가변적인지
- page의 레코드들을 빈 공간없이 packed할 지, 아니면 그대로 놔두어서 unpacked할 지

1.

-> 삭제 시, pack을 하면 record의 번호가 변경됨, 상위 layer에서도 record의 번호 수정 필요
-> independency X
2.
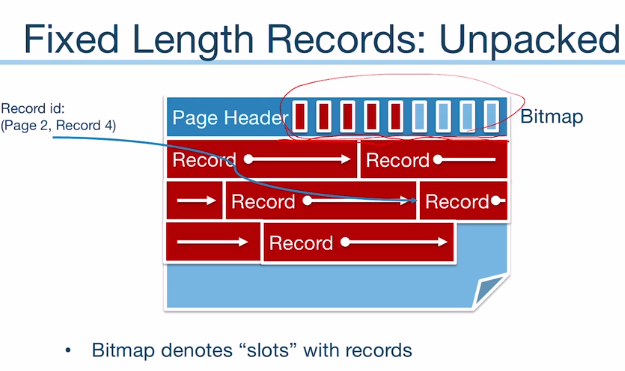
-> Bitmap을 이용해서 빈 공간 탐색 가능
-> Record의 길이가 짧아서 비트맵이 커지면 효율성 낮아짐
3.


-> footer에 slot을 이용하여 가변적인 record를 효율적으로 다룰 수 있다.
-> 마지막 slot에 몇개의 record가 저장되었는지, free space의 시작점이 어디인지, 반대 방향순으로 slot에 레코드의 길이+시작점을 기록한다.
-> slot과 record가 만나기 직전이 곧 최대 효율(현재의 대부분의 데이터베이스들이 slot을 사용하고 있음)
-> 빈 공간을 찾을 때, 기본적으로 free space를 가르키는 slot을 먼저 보고, 그 다음 빈 record slot을 본 뒤, 그래도 없다면 page reorganization을 수행한다.
Record의 레이아웃

시스템 카탈로그 = 스키마 저장 테이블
-> 자료형의 저장을 압축해서 표현하므로 저장 공간을 아낄 수 있음
고정 길이의 레코드 포맷

가변 길이의 레코드 포맷




-> 4번째는 스키마를 참고하여 헤더의 끝부분과 고정 자료형의 끝을 알 수 있고, 헤더의 주소값을 통해 가변형 자료형의 위치를 알 수 있어 스캔이 매우 빨라진다.
정리
